The JSON Routine File Processor is the final project
of the ENGG*1420 OOP Course I took in the winter
2023 semester at the UoG. It was developed by a team
of 6. The program is written entirely in Java and
makes use of the Laserfiche company's remote
repository API. The program has the ability to read
in a .JSON file using the Jackson JSON parser for
Java. The structure from the JSON is stored in a
Plain Old Java Object (POJO) hierarchy that extracts
the relational structure from the JSON. The POJO
structure is then passed off the Sequencer that
converts the POJO structure into a class hierarchy
using feature rich classes that possess methods to
process data.
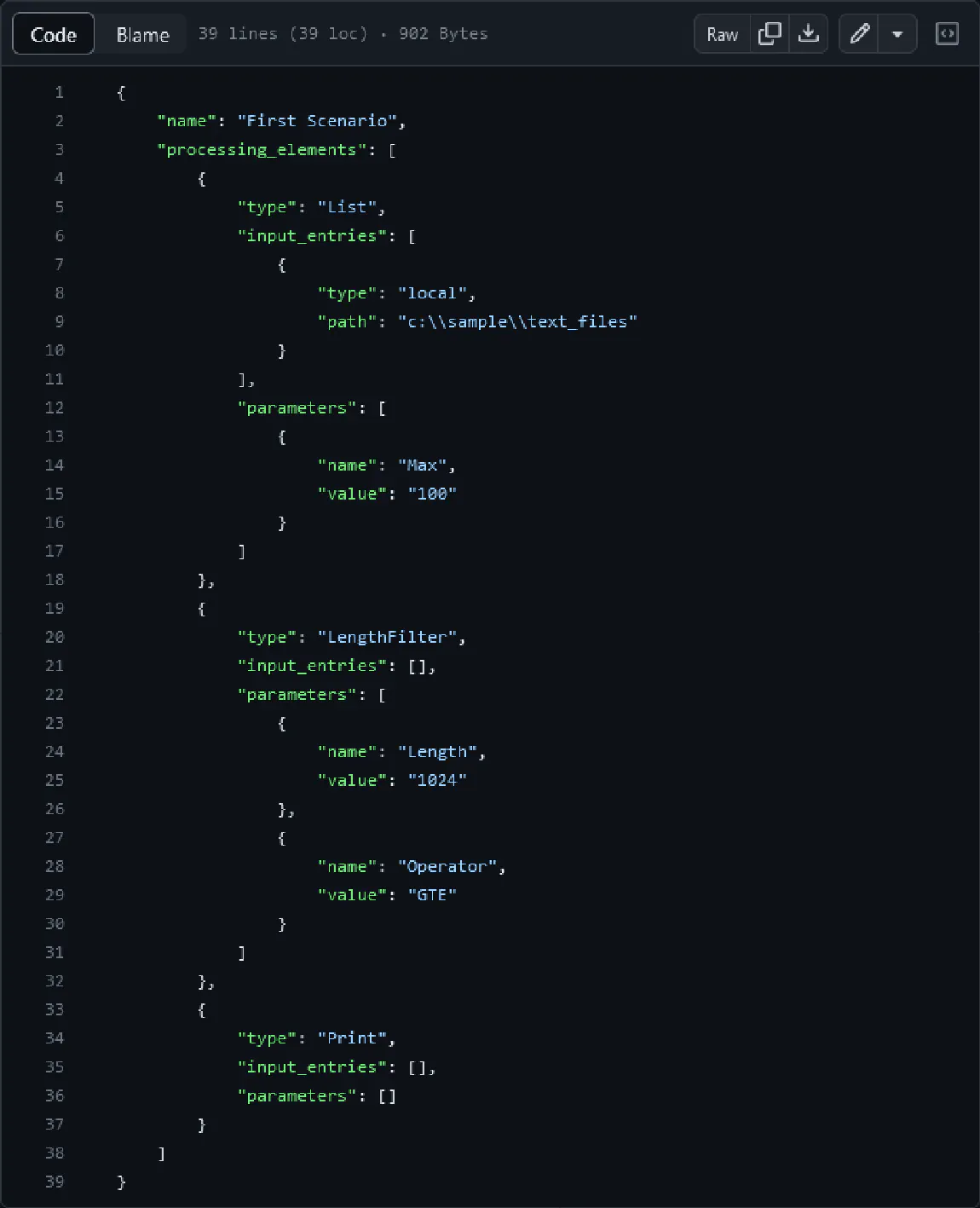
The .JSON file contains all the instructions for a
given processing scenario. Every scenario is broken
up into processing elements. A processing element
performs an action. It might act as a filter, or
print out information, or list child directories or
files. Each Processing element is required to have
input entries and parameters. The input entries can
be either remote or local entries. Any entry can
either be a file or a directory (folder). This
yields a total of 4 possible identities for an
entry. This means an Entry is either a local File,
local Folder, remote File, or remote Folder. The
JSON file then provides the parameters of the
processing element, which are specific to each type
of processing element. One thing to note is that
only the first processing element needs to provide
the input entries. All subsequent processing
elements will take their input directly from the
output of the previous processing element.
This project made heavy use of GitHub to control the
versions of the program while it was in development.
Many of the team members were writing new code and
changing existing code in parallel with others
simultaneously. We made heavy use of branches and
only merged in changes to the main branch once a
given feature was complete.
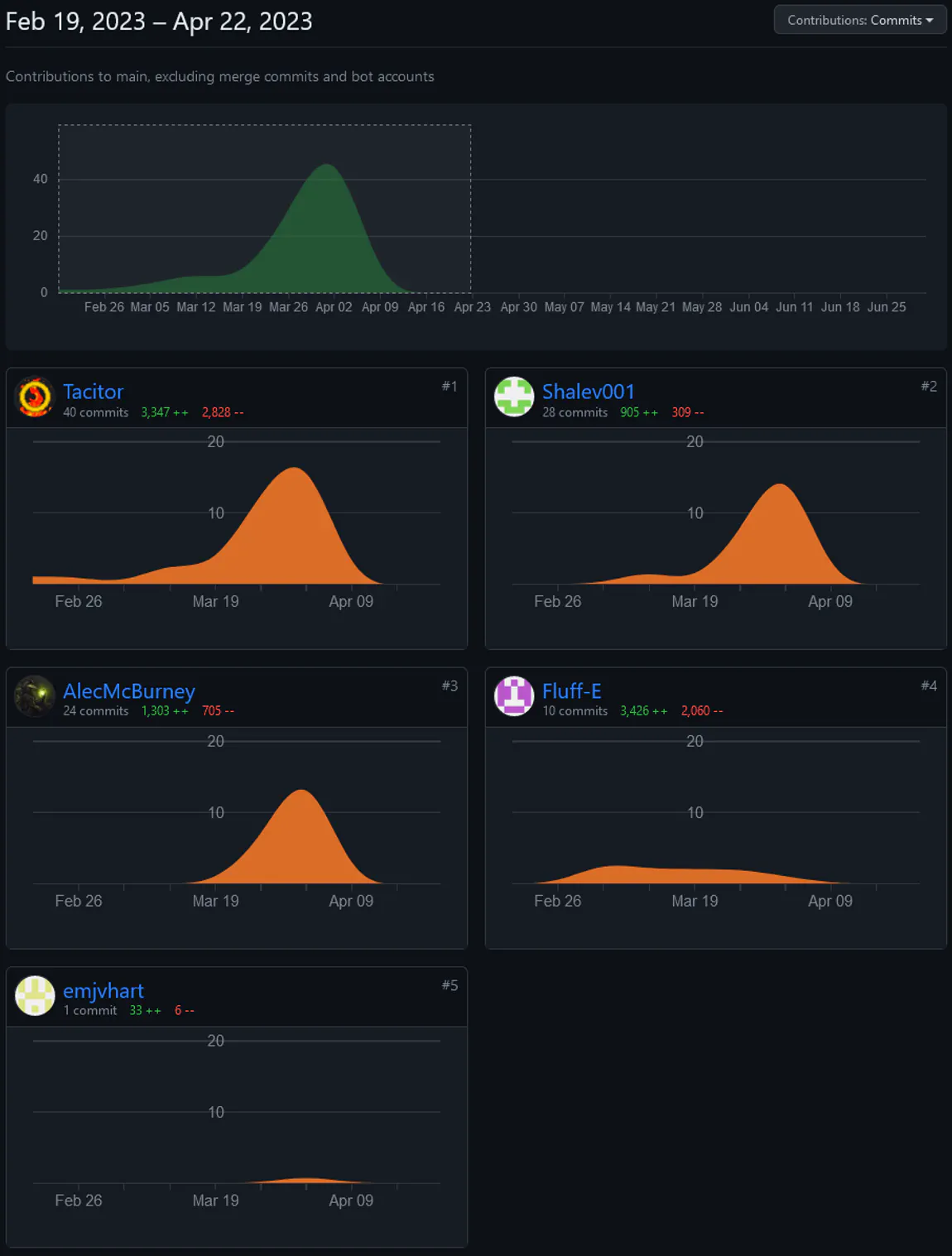
This project has the most intertwined and convoluted
network graph of any other project I have worked on
to date. This is a result of the large amount of
parallelization and simultaneous work as all 6
members were working on the project. If you scroll
all the way to the right on the network graph it
even appears that some commits were made weaving in
and out of April 2nd and 3rd. Quite frankly I am not
sure what causes this strange time travel behavior
to appear as such on the graph.
Another interesting aspect of this project is that
it is able to interface with a remote repository
from the Laserfiche company. These repos have a very
novel file structure. In a given repository each
entry is identified exclusively with an entry ID.
There is no file structure, or access to the nested
folder. If a folder contains other entries, then
this is discovered by using the API to specifically
query for child entries. These child entries can
again just be directly accessed with the Entry ID
without needing to even know it exists withing a
folder. These quirks made it very interesting to get
both local entries and remote entries interoperable.